Building a Secure and Resilient AI Edge Compute Environment

Jeff Zeller | April 24th, 2025
In this modern era, when we talk about AI deployment, people are more likely to associate it with massive cloud computing clusters, huge investments in data center construction, and the number of H100s owned. However, to bring AI into the real world, we often need a “bridge” to close the gap between those giant machines and the cameras and robot arms on the production line. At Matroid, we call these “AI Edge Compute Units”.
Challenges of AI Edge Compute
Many of today’s devices, even those with relatively small form factors, such as smartphones, have enough processing power for AI computations. However, computing power is not the only factor we need to consider, given the diverse environment the device needs to adapt to. Let’s take a closer look at some of the details.
Numerous Devices Distributed Across Various Locations
When deploying Edge Units, we anticipate a significant number of devices necessary to meet operational requirements. It’s not merely a matter of one or two units; each site and customer may necessitate the deployment of at least a dozen Edge Units, potentially even more. This large-scale deployment introduces complexities in management and support, particularly for remote troubleshooting and maintenance across geographically dispersed locations.
Software/Configuration Updates
Updating configurations on numerous edge devices across vast geographical areas can be challenging. Human errors are inevitable and in normal compute deployment, usually correctable; however, for edge units, they could be irreversible and thus, catastrophic. For instance, an incorrect network configuration could permanently disable the machine, necessitating physical replacement and resulting in downtime and wasted human resources.
Managing Hardware Resources For The Long Run
Edge units, unlike cloud computing, have limited resources and need to operate continuously for extended periods. This means that software issues, such as workloads consuming excessive resources, need to be managed to ensure the system remains operational.
Accidental Network/Power Loss, and Recovery Plan
Edge units can be unexpectedly unplugged or experience power failures. Regardless of the cause, the unit should always recover to its normal state as quickly as possible after a power outage.
Security Measurement and Exploitation Prevention
The security of edge units is critical. Because edge units can connect to multiple environments at the same time, they can be vulnerable to exploitation. A compromised edge unit could result in data leaks and real-world safety concerns due to its role in automation systems. Therefore, a trusted compute environment is essential.
Our OS Architecture
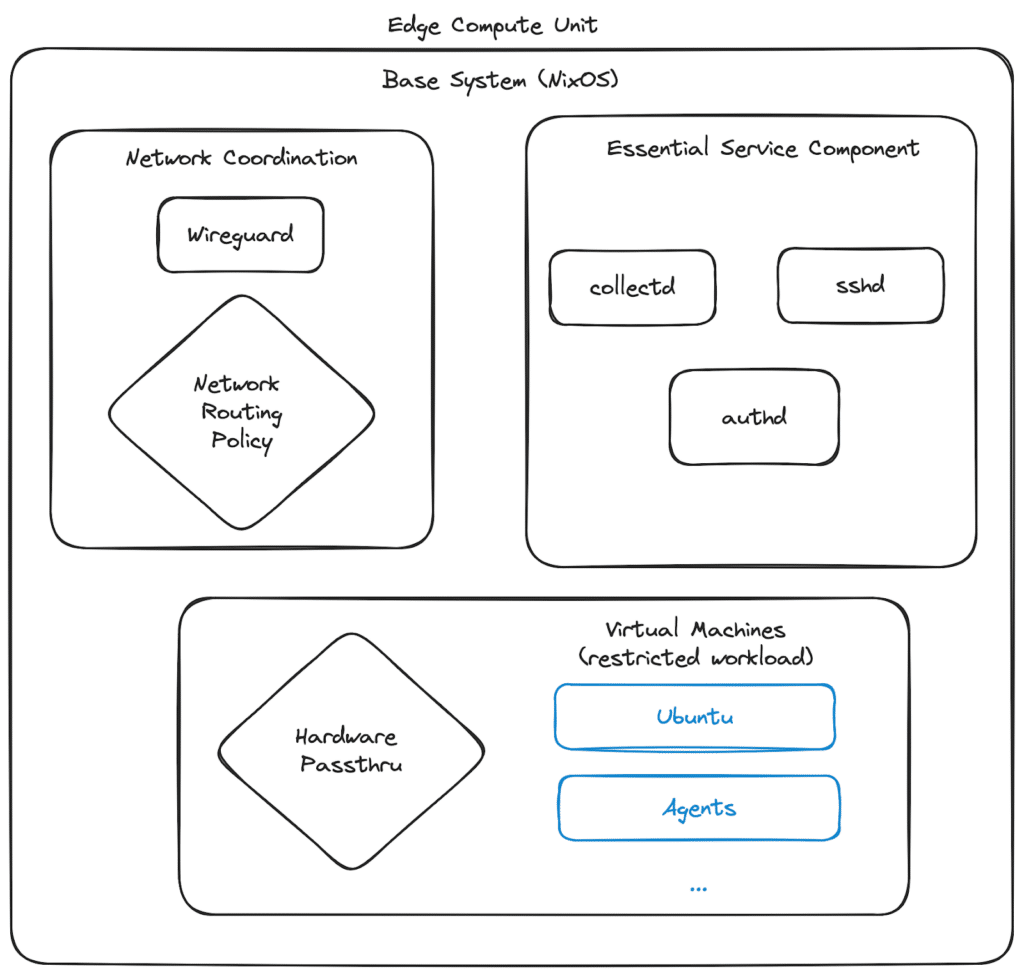
In our setup, the whole base system is built upon NixOS. NixOS uses a declarative configuration model, making system configurations reproducible. It solves some of the problems we mentioned above:
Reproducibility: The declarative approach of NixOS configurations guarantees system reproducibility across diverse environments and timeframes by mitigating configuration drift. Reproducible artifacts enable consistent environment simulation within development contexts and streamline security audits, assuring that the third-party audit environment mirrors the production environment.
Consistency and Reliability: By providing a reliable mechanism for reproducing system configurations, NixOS minimizes the risk of inconsistencies and errors that can arise from manual configuration or ad-hoc changes. This leads to a more stable and dependable edge computing environment, where AI applications can operate reliably with minimal downtime.
Simplified Management: The declarative model simplifies the management of system configurations, making it easier to track changes, roll back to previous states, and deploy updates consistently across multiple edge devices. This streamlines the operational aspects of managing AI edge compute environments, reducing the administrative overhead and potential for human error.
Some other advantages of NixOS for developers include:
Atomic Upgrades and Rollbacks: System updates are executed with complete atomicity, ensuring either successful implementation or failure without system compromise. System rollbacks are reliable and easily accomplished.
Read-only file system: The system’s boot process leverages a read-only file system partition to ensure its integrity after upload. This design choice protects against file system corruption caused by power outages. Additionally, the NixOS store model allows for thorough system integrity checks, enhancing security measures and preventing unauthorized access.
Minimized Software Footprint: NixOS optimizes system configurations by incorporating only essential software components. This optimization is particularly advantageous in remote environments with limited network reliability, leading to reduced resource consumption.
Virtual Machines: The Missing Pieces For Runtime Resource Management
NixOS, while being an excellent tool for managing the desired state of a machine, has traditionally faced challenges when it comes to controlling and managing the dynamic behavior of processes at runtime. To address this, we leverage NixOS’s orchestration capabilities to manage virtual machines, ensuring that each virtual machine is provisioned with appropriate CPU and memory constraints, as well as firewall/network setup. These constraints act as safeguards against runaway workloads, preventing them from consuming excessive resources, interfering M2M(Machine to Machine) communication and potentially impacting the stability of the system.
NixOS orchestration has the unique benefit of combining system-level setup and software configuration. For instance, you can include system kernel settings for hardware pass-through alongside virtual machine setup. This unified configuration approach simplifies infrastructure management for developers and serves as a clear and valuable reference point for future use.
Furthermore, by implementing these resource constraints and utilizing the base system’s remote login functionality, we establish a robust recovery mechanism. In the event of an issue within a virtual machine, we can remotely access the base system to diagnose the problem and take corrective action. This may involve debugging the virtual machine’s processes or, if necessary, completely rebuilding the virtual machine by replacing it with a new instance. This approach ensures that we can always maintain control over the system and recover from unexpected runtime behavior, minimizing downtime and ensuring the continuity of operations.
Mass Deployment and Management
NixOS provides a reproducible, consistent environment. To scale this, we use Colmena, one of many tools available for managing multiple machines within the NixOS ecosystem.
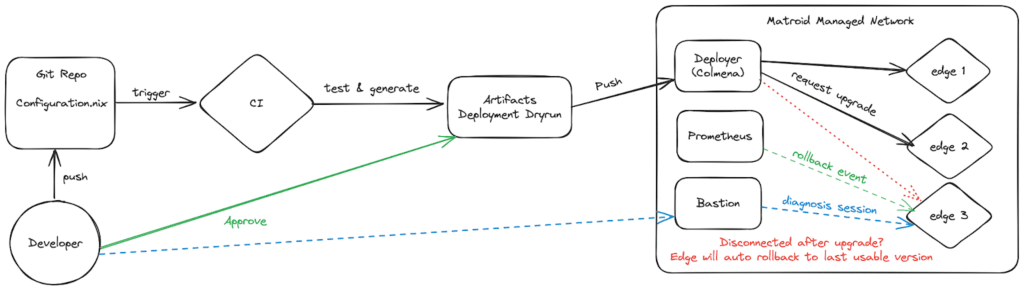
Here’s a potential workflow using Colmena:
- Define NixOS configurations for all edge units.
- Update Colmena hive.nix configuration to include new edge units in deployment.
- Push configuration to trigger CI
- CI runs Colmena to evaluate and build artifacts for testing and deployment.
- Developers approve the upgrade to release the deployment lock.
- Artifacts are pushed to the deployer, and the deployer requests each edge unit switch to the given OS enclosure.
- The device will roll back and record the incident if the switch is unsuccessful or the monitor is down (e.g. unable to communicate with the host).
- Grafana alert is triggered by this incident, and the developer can start a diagnosis session via bastion if necessary.
Colmena simplifies our deployment process through features like node tagging for A/B testing of the latest OS closure. We also integrate Colmena’s secret management capabilities with AWS Secret Manager, which allows for secure and automated secret rotation, further enhancing security by minimizing exposure of sensitive information and the risk of unauthorized access.
These automations significantly reduce the need for manual configuration intervention, saving valuable time and minimizing potential errors.
Conclusion
Building a secure and resilient AI edge compute environment presents unique challenges, but through a well-designed OS architecture leveraging NixOS and Colmena, we can effectively address them. This approach ensures reproducibility, consistency, and efficient management of edge devices, ultimately leading to a more reliable and secure deployment.
Advantages of NixOS and Colmena brought to us:
- Declarative configuration for system reproducibility.
- Atomic upgrades and rollbacks for system stability and human error prevention.
- Centralized configuration management with Colmena for consistency.
- Remote deployment capabilities for easier management.
- Scalable deployment for large numbers of devices.
- Minimal system components for resource optimization.
- Parallel deployment for efficiency.
- Reproducibility artifacts for security.
About the Author
Xinhao Luo is a software engineer at Matroid’s Infrastructure Team. When he’s not wrangling infrastructure challenges at work, you might find him grappling with the formidable electric bill from his homelab setup.
Building Custom Computer Vision Models with Matroid
Dive into the world of personalized computer vision models with Matroid's comprehensive guide – click to download today