Combining Language and Vision – Looking at CLIP

Darin Tay | February 11th, 2025
Introduction
The ability to combine both pictures and words is a powerful capability in many of the latest deep learning models. These models can analyze the pixels of your image to understand its content, analyze the words of your prompt to grasp what you are asking, and then fuse those understandings together to generate a response. While these models still have their limits, their capabilities would have been unimaginable only a few years ago.
CLIP, a text-image model published by OpenAI, has been the most impactful approach to fusing text and images. It is a useful standalone model that also underpins the vision-language capabilities in many of today’s multi-modal models, from Large Language Vision models like Llava to generative models like Stable Diffusion. Here, I’ll explore how CLIP works, its practical applications, and its limitations.
The Use-Case
Traditional image classifiers pre-define a fixed set of image categories and are trained using examples to classify images into those categories. It’s an effective process if you just want to distinguish between “cat” and “dog” pictures – but what if you need a model that works for arbitrary labels? Instead of fixed categories, could a model be trained to understand arbitrary text descriptions of categories?
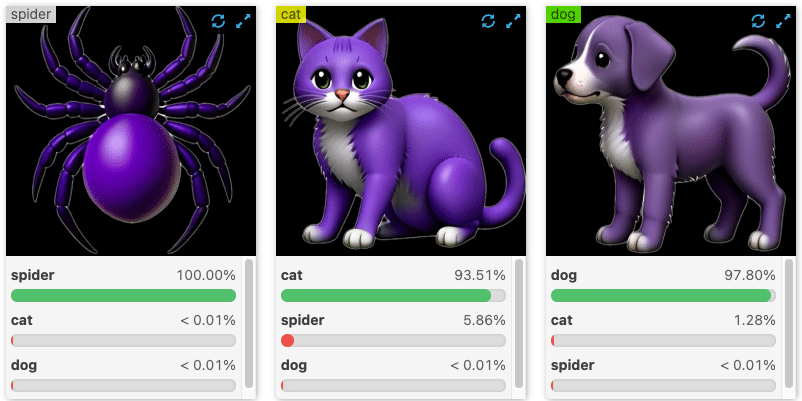
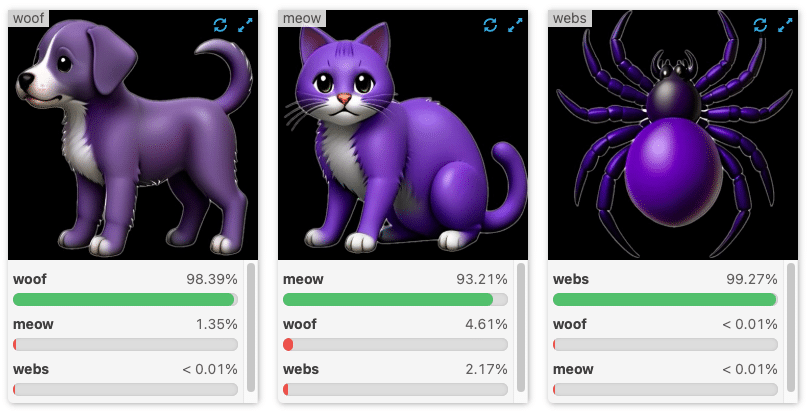
Before multi-modal text-vision models like CLIP, these fixed-label image classifiers were the best we had. Datasets with millions of images were manually tagged with a huge fixed set of labels like “cat”, “spider”, “fluffy”, etc., and trained with supervised learning techniques. This method works for those pre-defined labels but isn’t scalable. There are too many possible categories. These models don’t effectively learn the relationships between words or answer queries that don’t match their training data. They also don’t leverage the similarity between words to efficiently generalize their understanding.
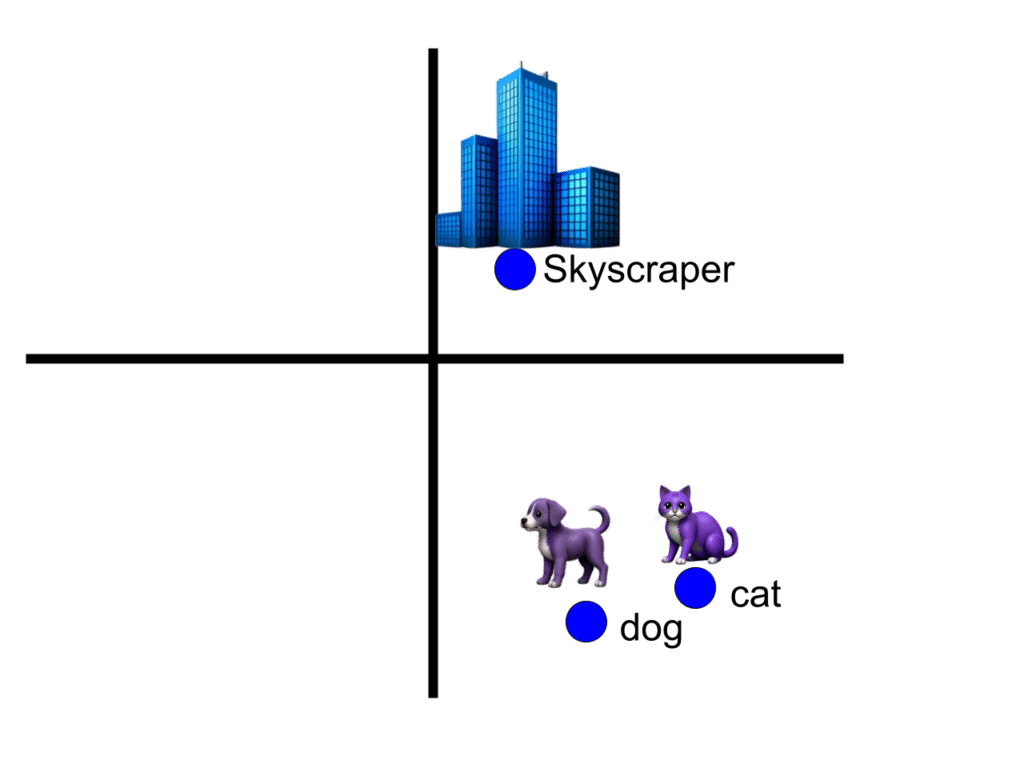
At the same time, research in both natural language and computer vision already had robust concepts of embeddings – representing words, sentences, and images as vectors, a sequence of numbers that encode “relevant” features such that similar objects have similar encodings. Embeddings for “cat” and “dog” would be closer to each other than to the embedding for “skyscraper” – whether they are embeddings for the words themselves or images portraying them. These embeddings give us a way to measure the ‘semantic similarity’ of two things by looking at the distance between their embeddings. However, embeddings are only comparable to other embeddings generated by the same model. The embedding of a cat image using an ImageNet derived model couldn’t be meaningfully compared to the word2vec embedding of the word “cat.”
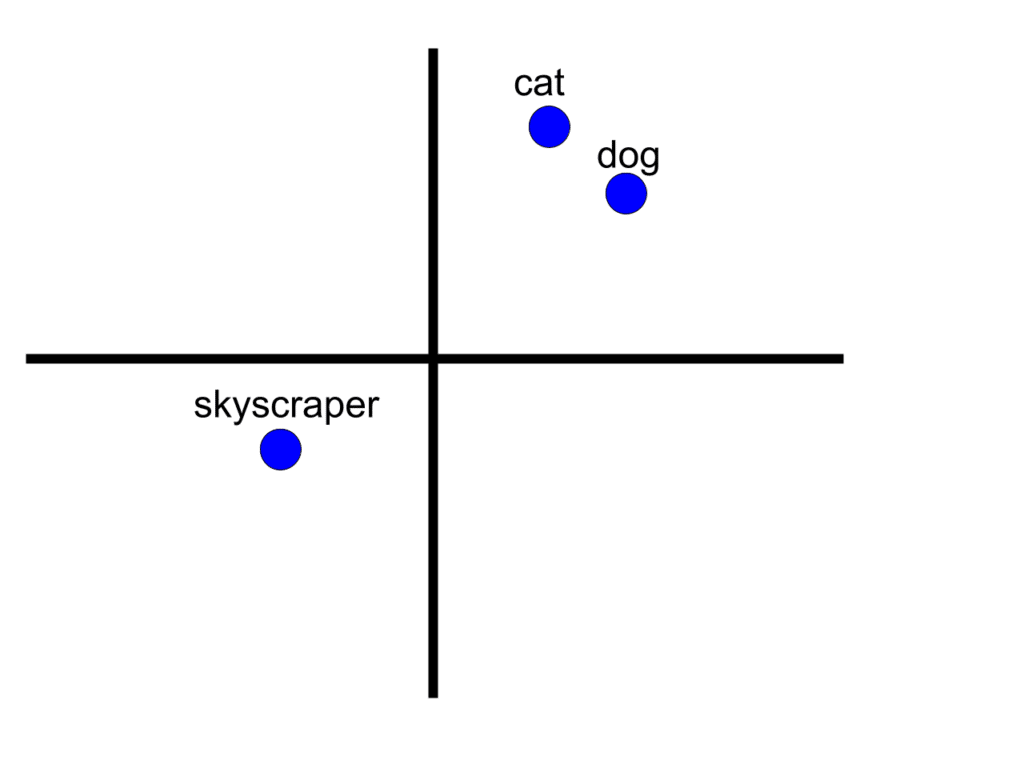
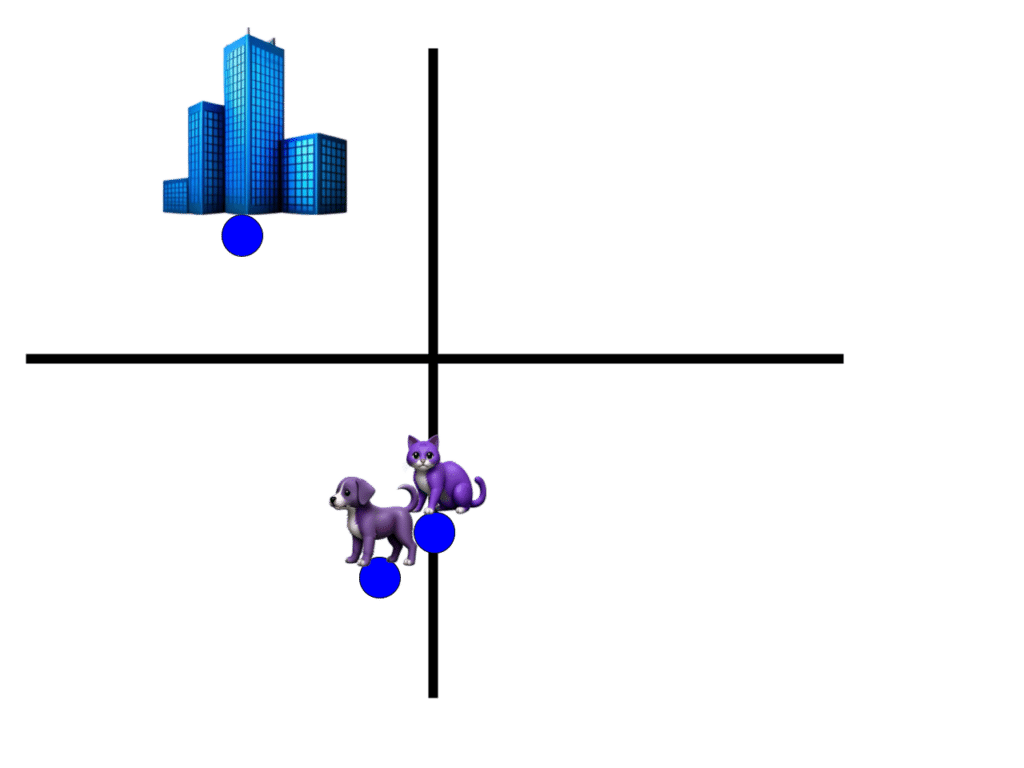
Similar concepts are nearby in each embedding space, but you cannot compare different ones.
CLIP – Contrastive Language-Image Pre-training
In 2021, OpenAI released their “Constrastive Language-Image Pre-training” (CLIP) model.
The basic idea is to take an internet-scale dataset of captioned images and train a model to generate the same embedding for the caption as it does for the corresponding image. The result is a model that embeds both text and images into a shared feature space.
This immediately enables powerful applications. For example, we can generate an embedding for an image, compare it to a list of text embeddings, and determine which text best describes the image. This approach allows for classification based on arbitrary phrases instead of a predefined set of categories.
Getting more technical for a moment, the CLIP training process uses contrastive loss to ensure that the embeddings of a caption and its corresponding image end up near each other and far away from other unrelated captions and images. For each training step, the model input is a batch of N (image, caption) pairs, and the output is an embedding of each image and caption. The training objective is to maximize the cosine similarity of the true image-text pairings and minimize the similarity of all other pairings in the batch. This training process is the important part – the actual model architecture of the text encoder and image encoder is an interchangeable implementation detail.
This simple process works remarkably well. Much of the CLIP paper describes the new state-of-the-art results it can achieve across a variety of computer vision tasks and applications. It isn’t just memorizing image-caption pairs during training, but instead developing a shared representation of image and text that generalizes beyond the examples it was trained on. Points in this feature space encode both an image and the words describing that image, which has very powerful applications.
CLIP as a Classifier – Applications and Limitations
For images and texts similar to the ones it was trained on, CLIP works almost like magic. If I want to distinguish between “red cars” vs “blue cars” or “sports car” vs “SUV,” the model just works. Where previously I needed to collect examples and train an application-specific image classifier, now I can just describe that I want to distinguish between an “open door” and a “closed door,” or tell me, “is something on fire in this image?”, and I instantly have something usable.
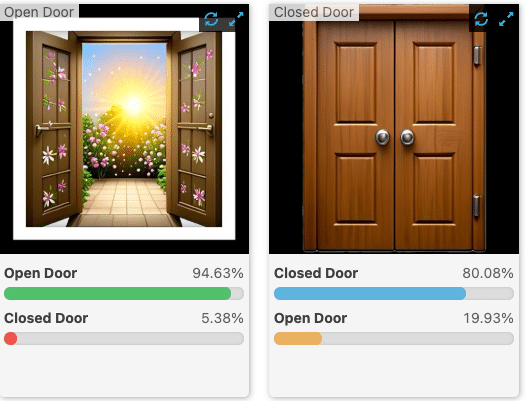
For more complex, domain-specific detections, off-the-shelf CLIP models are not a standalone solution. They are still limited by their training data and by their pretraining objectives. Remember that these models are trained on “captioned images on the internet.” The more dissimilar your domain is from that, the worse these models will perform. Be aware that many examples you see online about this model (including in this article!) are cherry-picked to make their point.
If you try to use one of these models to detect subtle anomalies in your manufacturing process, you will be disappointed. It will not tell you the physical dimensions of your dent, and may struggle to differentiate between a scratch and the normal texture of your material. CLIP does not train well for spatial reasoning. They can often distinguish between an image containing “a couple of cats” vs one with “tons of cats,” but don’t expect them to accurately count exactly how many cats are in the image.

Resolution is also an important limiting factor. CLIP has some limited OCR capabilities, but it is hindered by the low resolution it operates at – often as low as 224×224 pixels – preventing small text from being legible. Other fine details in images are lost during resizing, making them inaccessible to the model when applied naively.
Thresholding and Relevance
Another challenge with using CLIP and similar models is interpreting the ‘similarity scores’ it outputs. Anyone who has worked with detection models is familiar with confidence scores. While these are often uncalibrated and mistakenly interpreted as probabilities, they are at least consistent enough that you can use rules of thumb or develop an intuition as to what constitutes a ‘likely’ detection. The same is not true for CLIP models, particularly as your queries deviate from what the model was trained on.
Many demonstrations of this technology look at relative scores. Is the “cat” score higher than the “dog” score in this image? Or which image in my dataset has the highest “zebra” score? Looking at relative scores instead of absolute can avoid this issue, but is not always a useful solution.
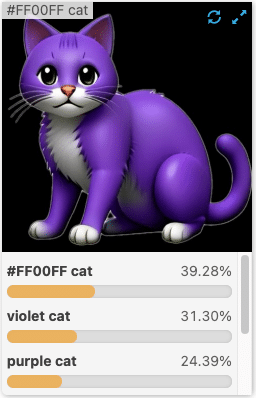
To robustly set similarity score thresholds, you really want to put together a dataset specific to your use-case and generate standard evaluation metrics – but then we’re back to labeling and curating datasets, which we wanted to avoid.
Finding clever and general ways to solve this problem is key to making use of CLIP directly. Fortunately, many downstream tasks don’t need to solve this problem to make use of CLIP embeddings and take advantage of their fused image/text representations.
CLIP for Semantic Similarity
There are many systems out there using CLIP as the basis for their text-image similarity searches. These embeddings are a great solution for efficiently filtering images from a massive collection based on text descriptions. If I want to find that “night-time picture of a cat sleeping on a snowman” that I know is in my collection somewhere, it works like a charm!
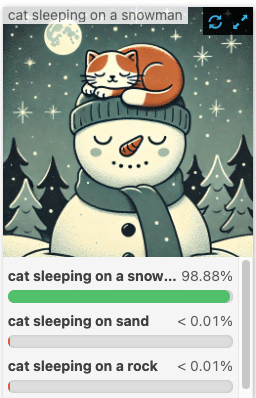
These systems work by using CLIP’s image encoder to generate embeddings for every image in the collection and inserting those embeddings into a vector database. Once that is done, any text query can be very quickly answered by generating the text embedding and searching our database for the N most similar image embeddings. Vector databases are incredibly efficient at this operation.
Of course, most of the same limitations of using CLIP as a classifier apply here, too. Thresholding is still important for determining where to cut off the results. The effectiveness of the search will often depend on how unique your dataset is and how complex the queries you need to match. Subtleties are not captured by the model, and the metric often struggles to correctly order results when many of them are close. But even with those caveats, it’s still remarkably good and wildly better than what came before it.
Conclusion
Since this groundbreaking approach was first published, the research community has made many improvements. While the core concepts remain the same, researchers have taken these ideas and refined them, making models that are more accurate, faster, or in some other way better. Additionally, many diverse and unexpected applications of the model have been found. CLIP-extracted features are used as the basis for video understanding, prompt-guided image generation, large language vision models, zero-shot segmentation models, and more.
While we don’t have time here to get into all of those extensions to the model, we’ve covered the basics here to understand what you can do with CLIP and how it works. While it cannot reliably solve everything by itself, it is a valuable tool in your computer vision toolbox and a great starting point for more powerful capabilities.
At Matroid, part of what we do is keep on top of these advances in AI and computer vision and figure out how the ideas and concepts can be applied to solve the industry-specific use-cases encountered by our customers. Combining language and vision with techniques like those pioneered by CLIP enables a lot of capabilities – we work to transform these innovations into reliable, practical solutions powered by our computer vision platform.
About the Author
Darin Tay is the Director of Infrastructure and Deep Learning at Matroid.
Download Our Free
Step By Step Guide
Building Custom Computer Vision Models with Matroid
Dive into the world of personalized computer vision models with Matroid's comprehensive guide – click to download today